Bst-деревей
Cтраница 2
Задача обеспечения гарантированной производительности для реализаций таблиц символов, основанных на использовании BST-деревьев, - превосходный повод для исследования того, что именно подразумевается под гарантированной производительностью. Будут показаны решения этой задачи, являющиеся типичными примерами трех базовых подходов к обеспечению гарантированной производительности при разработке алгоритмов: рандомизации, амортизации и оптимизации. А теперь давайте по очереди кратко рассмотрим каждый из этих подходов. [16]
Основная идея заключается в представлении 2 - 3 - 4-деревьев в виде стандартных BST-деревьев ( содержащих только 2-узлы), но с добавлением к каждому узлу дополнительного информационного разряда для кодирования 3-узлов и 4-узлов. Мы будем представлять связи двумя различными типам связей: красными ( red) связями ( R-связями), которые объединяют воедино небольшие бинарные деревья, образующие 3-узлы и 4-узлы, и черными ( black) связями ( В-связями), которые объединяют воедино 2 - 3 - 4-дерево. [17]
В соответствии с леммой 12.6 следует ожидать, что затраты на поиск для BST-деревьев должна быть приблизительно на 39 % выше затрат для бинарного поиска произвольных ключей. Но в соответствии с леммой 12.7 дополнительные затраты вполне окупаются, поскольку новый ключ может быть вставлен почти при тех же затратах - подобная гибкость при использовании бинарного поиска не доступна. На рис. 12.8 показано BST-дерево, полученное в результате длинной цепи произвольных перестановок. Хотя оно содержит несколько длинных и несколько коротких путей, его можно считать хорошо сбалансированным: для выполнения любого поиска требуется менее 12 сравнений, а среднее количество сравнений, необходимых для обнаружения произвольного попадания при поиске равно 7.00, что сравнимо с 5.74 для случая бинарного поиска. [18]
Несмотря на все описанные преимущества, имеется одно важное обстоятельство, которым мы пренебрегли при рассмотрении использования BST-деревьев, patricia - деревьев или TST-деревьев для типичных приложений индексирования текста: сам по себе текст фиксирован, поэтому нет необходимости поддерживать динамические операции insert, как мы привыкли это делать. То есть, как правило, индекс строится один раз, а затем без каких-либо изменений используется для выполнения огромного объема поисков. Следовательно, динамические структуры данных типа BST-деревьев, patricia - деревьев или TST-деревьев могут оказаться вообще не нужными. [19]
Производительность для худшего случая деревьев, построенных по методу поразрядного поиска, значительно выше производительности для худшего случая BST-деревьев, если количество ключей велико, а длина ключей мала по сравнению с их количеством. Вероятней всего, во многих приложениях ( например, если ключи образованы случайными значениями разрядов) длина самого длинного пути в DST-дереве оказывается сравнительно небольшой. В частности, самый длинный путь ограничивается длиной самого длинного ключа; более того, если ключи имеют фиксированную длину, то время поиска ограничивается длиной. [20]
Разряды ключей управляют поиском и вставкой, но обратите внимание, что DST-деревья не обладают свойством упорядоченности, характерным для BST-деревьев. Другими словами, ключи в узлах слева от данного не обязательно меньше, а ключи в узлах справа от данного не обязательно больше ключей данного узла, как это было бы в BST-дере-ве с различными ключами. Ключи слева от данного узла действительно меньше ключей справа от него - если узел находится на уровне k, все они совпадают в первых k разрядах, но следующий разряд равен 0 для ключей слева и I для ключей справа - но сам ключ узла может быть наименьшим, наибольшим или любым в диапазоне всех ключей из поддерева этого узла. [21]
Пример 2 - 3 - 4-дерева приведен на рис. 13.10. Алгоритм поиска ключей в таком дереве представляет собой обобщение алгоритма поиска для BST-деревьев. Чтобы выяснить, находится ли ключ в дереве, мы сравниваем его с ключами в корне: если он равен любому из них, имеет место попадание при поиске; в противном случае мы отслеживаем связь от корня к поддереву, соответствующему набору значений ключей, который должен содержать искомый ключ, и рекурсивно выполняем поиск в этом дереве. Существует ряд способов представления 2 -, 3 - и 4-узлов и для организации поиска соответствующей связи; отложим рассмотрение этих решений до раздела 13.4, где приводится особенно удобная организация поиска. [22]
В этом разделе мы рассмотрим деревья поиска, которые позволяют использовать разряды ключей для проведения поиска подобно DST-деревьям, но ключи которых упорядочены, что позволяет поддерживать рекурсивные реализации функции sort и других функций таблиц символов, как это делалось в отношении BST-деревьев. Основная идея заключается в хранении ключей только в нижней части дерева, в листьях. Результирующая структура данных обладает рядом полезных свойств и служит основой для нескольких эффективных алгоритмов поиска. Впервые структура была создана Брианде ( Briandais) в 1959 г., и поскольку она оказалась удобной для поиска ( re / r / eval), в 1960 г. Фредкин ( Fredkin) применил к ней специальное название trie. С некоторой долей юмора обычно это слово произносится как трай-и ( try - попытка, англ. Вероятно, в соответствии с принятой в книге терминологией, подобного рода деревья следовало бы называть trie - деревьями бинарного поиска, тем не менее, повсеместно используется термин trie - дерево и все его понимают. В этом разделе рассматривается базовая бинарная версия, в разделе 15.3 - важную вариацию, а в разделах 15.4 и 15.5 - базовую версию trie - деревьев со многими путями и ее вариации. [23]
ОРИЕНТАЦИИ РАЗЛИЧНЫ) казан на рис. 13.8. Различие между вставкой с расши - В этом простом дереве ( вверху) рением и стандартной вставкой в корень может показаться несущественным, но оно достаточно важно: расширение исключает худший случай квадратичной зависимости времени выполнения, являющийся главным недостатком стандартных BST-деревьев. [24]
На рис. 13.13 представлено посроение 2 - 3 - 4-дерева для тестового набора ключей. В отличие от стандартных BST-деревьев, которые разрастаются вниз от вершины, эти деревья разрастаются вверх от нижней части. Поскольку 4-узлы разделяются на пути от вершины вниз, деревья называются нисходящими 2 - 3 - 4-деревьями. Этот алгоритм важен, поскольку он создает практически идеально сбалансированные деревья поиска, хотя в процессе прохождения по дереву выполняются всего лишь несколько локальных преобразований. [25]
Лемма 12.8 В худшем случае для поиска в дереве бинарного поиска с N ключами может требоваться N сравнений. На рис. 12.9 и 12.10 показаны два примера наихудших случаев BST-деревьев. [26]
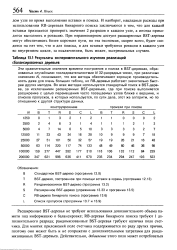 |
Результаты экспериментального изучения реализаций. [27] |
Эти сравнительные значения времени построения и поиска в BST-деревьях, образованных случайными последовательностями Л / 32-разрядных чисел, при различных значениях Л /, показывают, что все методы обеспечивают хорошую производительность даже для очень больших таблиц, но RB-деревья работают значительно быстрее других методов. Во всех методах используется стандартный поиск в BST-дере-ве, за исключением расширенных BST-деревьев, где при поиске выполняется расширение с целью перемещения часто посещаемых узлов ближе к вершине, и списков пропусков, в которых используется, по сути дела, этот же алгоритм, но по отношению к другой структуре данных. [28]
Один из главных недостатков рандомизованной вставки - затраты на генерацию случайных чисел в каждом из узлов во время каждой вставки. Высокопроизводительный системный генератор случайных чисел может работать с большой нагрузкой для генерации псевдослучайных чисел с большей степенью случайности, чем требуется для BST-деревьев. Поэтому в определенных реальных ситуациях ( например, если допущение о случайном порядке следования элементов справедливо) конструирование рандомизованного BST-дерева может оказаться более медленным процессом, чем построение стандартного BST-дерева. Подобно тому как это делалось в случае быстрой сортировки, эти затраты можно снизить, используя числа, которые не являются совершенно случайными, но не требуют больших затрат при генерации и достаточно подобны случайным числам. [29]
Расширенные BST-деревья не требуют использования дополнительного объема памяти под информацию о балансировке; RB-деревья бинарного поиска требуют 1 дополнительного разряда; рандомизованные BST-деревья требуют наличия поля счетчика. Для многих приложений поле счетчика поддерживается по ряду других причин, поэтому оно может быть и не сопряжено с дополнительными затратами для рандо-мизованных BST-деревьев. [30]
Страницы: 1 2 3