Запись - база - данные
Cтраница 3
 |
Способ хранения сегментов записи базы данных, изобра. [31] |
При использовании иерархических последовательных методов доступа сегменты записей базы данных располагаются рядом, все сегменты логической записи принадлежат одной и той же записи базы данных, а положение физических блоков устанавливается указателями. Метод дает возможность осуществить как последовательный, так и индексно-последовательный доступ, рациональное использование носителя в условиях блокированных файлов. [32]
В СУБД - значение одного или нескольких полей записи базы данных, идентифицирующее эту запись и являющееся входом в CALC-процедуру. [33]
 |
Основные типы операций ввода-вывода. [34] |
Следовательно, вероятности операций ввода-вывода определяются для некоторой усредненной записи базы данных. [35]
Выражение индекса используется для вычисления значения ключа для каждой записи базы данных. Результатом вычисления выражение должно быть значение одного из следующих типов: числовое, строковое, дата или булево. Выражение фильтра должно возвращать результат типа булево. Если значение выражения фильтра для конкретной записи базы данных равно истине, информация об этой записи будет включена в индексный файл, в противном случае индексный файл не будет содержать информацию об этой записи и позиционирование на эту запись XBase-объекта с данным текущим индексом производиться не будет. [36]
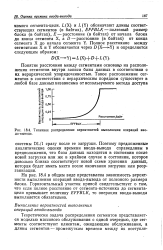 |
Типичное распределение вероятностей выполнения операций ввода-вывода. [37] |
Понятие расстояния между сегментами основано на расположении сегментов внутри записи базы данных в соответствии с их иерархической упорядоченностью. [38]
Второе средство представляет собой совокупность указателей, связывающих сегменты записи базы данных. [39]
Ключ - одно или несколько полей, однозначно определяющих каждую запись базы данных. [40]
При иерархической последовательной организации с применением HSAM или HISAM сегменты записи базы данных связываются друг с другом посредством соответствующего расположения в среде хранения. [41]
После этого изменения будут внесены, а курсор переместится в следующую совпавшую запись базы данных. [42]
 |
База данных HI DAM. [43] |
Иерархически прямая организация, как и HIDAM, предусматривает соединение сегментов записи базы данных иерархическими указателями либо указателями вида порожденный / подобный по выбору пользователя. Существенное различие между HIDAM и HDAM заключается в том, что в HDAM индекс, обеспечивающий доступ к корневым сегментам, заменяется на хеш-функцию. Пространство памяти для базы данных HDAM подразделяется на первичную и вторичную области. Для каждого возможного значения, возвращаемого хеш-функцией, существует один первичный блок и столько блоков переполнения, сколько затребовал проектировщик. Блоки переполнения имеются в распоряжении для участков, соответствующих любому хеш-значению. [44]
ЭВМ, Мпк; производительность процессора по произвольному поиску и корректировке записей базы данных Япр, равная 50 - 60 записей в минуту; количество строк АЦПУ, приходящихся на одну запись базы данных, выводимую на печать, Л1Печ; число записей базы данных, которое необходимо ежедневно выводить на печать, Л13; число записей массива готовой продукции Мг. Ма; производительность процессора при выполнении программы Подготовка отчета о состоянии запасов Я3, равная 100 - 240 записей в минуту; производительность процессора при последовательном чтении записей массива готовой продукции Пи, равная 2400 записей в минуту. [45]
Страницы: 1 2 3 4