Предыдущий алгоритм
Cтраница 3
Система с использованием покомбинационного сравнения и исправления обладает наименьшей эффективностью по сравнению с предыдущими алгоритмами декодирования. [31]
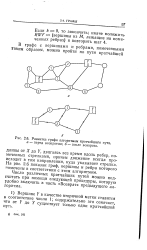 |
Разметка графа алгоритмом кратчайшего путя. а - перед возвратом. б - после возврата. [32] |
Число различных кратчайших путей можно подсчитать при помощи следующей процедуры, которую удобно включить в часть Возврат предыдущего алгоритма. [33]
Система поиска локальных экстремумов 6 () в этом алгоритме совпадает с системой поиска, описанной в предыдущем алгоритме. [34]
Опыт авторов в оптимальном проектировании говорит о том, что коль скоро задача проектирования подходящим образом сформулирована, ее решение можно найти при помощи умеренного числа итераций при применении предыдущего алгоритма. [35]
Преимущество этого алгоритма заключается в том, что он не оказывает дополнительной нагрузки на сеть в критический период. Предыдущий алгоритм обращался с новыми запросами в сеть как раз тогда, когда загрузка узлов и сети была и без того высока. В данной схеме вероятность появления незагруженной машины в перегруженной системе мала. Однако если такое вдруг случается, простаивающая машина легко найдет себе работу в такой ситуации. Конечно, когда почти вся система простаивает, алгоритм, в котором инициатором выступает получающая сторона, создает существенный трафик поиска работы. И все же значительно лучше иметь накладные расходы в недогруженной системе, чем в перегруженной. [36]
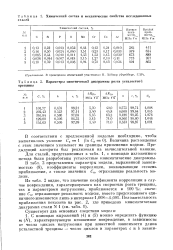 |
Параметры кинетической диаграммы роста усталостно3 трещины. [37] |
Величина расхождения с этим значением указывает на границы применения модели. Предыдущий алгоритм был реализован на вычислительной машине. [38]
Преимущество этого алгоритма заключается в том, что он не оказывает дополнительной нагрузки на сеть в критический период. Предыдущий алгоритм обращался с новыми запросами в сеть как раз тогда, когда загрузка узлов и сети была и без того высока. В данной схеме вероятность появления незагруженной машины в перегруженной системе мала. Однако если такое вдруг случается, простаивающая машина легко найдет себе работу в такой ситуации. Конечно, когда почти вся система простаивает, алгоритм, в котором инициатором выступает получающая сторона, создает существенный трафик поиска работы. И все же значительно лучше иметь накладные расходы в недогруженной системе, чем в перегруженной. [39]
Значительно лучшими характеристиками в этой области обладают алгоритмы типа Ньютона, в которых строится последовательность вспомогательных экстремальных задач о максимуме функции, аппроксимирующей целевую функцию в окрестности точки поиска, причем в отличие от алгоритма проекции градиента эта аппроксимация содержит линейные и квадратичные члены. Аналогично предыдущему алгоритму связи и ограничения линеаризуются. [40]
Очевидно, этапы вычислений нельзя заранее перечислить, если не фиксировать значение / г, тем не менее этот процесс можно описать с выделением фиксированного числа различных, но многократно повторяющихся этапов. Анализ предыдущего алгоритма показывает, что на каждом из этапов 2 - 4 выполняются одни и те же действия, но с использованием разных коэффициентов полинома, точнее говоря - коэффициентов с разными индексами. Поэтому вместо них можно ввести только один этап, который осуществляет один шаг по схеме Горнера с использованием коэффициента а -, номер i которого заранее не фиксируется, а определяется по некоторому правилу к началу выполнения данного этапа. [41]
Ключевым препятствием в реализации корневой сортировки служит ее неэффективность по памяти. В предыдущих алгоритмах сортировки дополнительная память нужна была разве что для обмена двух записей, и размер этой памяти равняется длине записи. Теперь же дополнительной памяти нужно гораздо больше. Если стопки реализовывать массивами, то эти массивы должны быть чрезвычайно велики. На самом деле, величина каждого из них должна совпадать с длиной всего списка, поскольку у нас нет оснований полагать, что значения ключей распределены по стопкам равномерно, как на рис. 3.2. Вероятность того, что во всех стопках окажется одинаковое число записей, совпадает с вероятностью того, что все записи попадут в одну стопку. [42]
В отношении связанности формы данный алгоритм уступает предыдущему, так как требует специальных приемов для метрической увязки размеров в единое целое. Монолитный характер формы предыдущего алгоритма позволяет достигнуть правильности деталей самой последовательностью процедур построения. Построение формы, составляющие элементы которой структурно тождественны, с помощью сложения не эффективно, поскольку требует применения к каждому построенному элементу дополнительных контрольных операций метрического согласования с базовой структурой. Наоборот, форму, основанную на ясно воспринимаемом сопоставлении несомых и несущих элементов, целесообразно выполнять с помощью алгоритма сложения. [43]
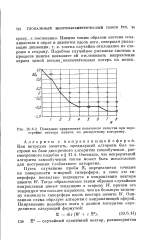 |
Поведение приращения показателя качества при перестройке вектора памяти по дискретному алгоритму. [44] |
Как нетрудно заметить, предыдущий алгоритм был построен на базе дискретного алгоритма самообучения, рассмотренного подобно в § 17.4. Очевидно, что непрерывный алгоритм самообучения также может быть использован для построения глобального алгоритма. [45]
Страницы: 1 2 3 4